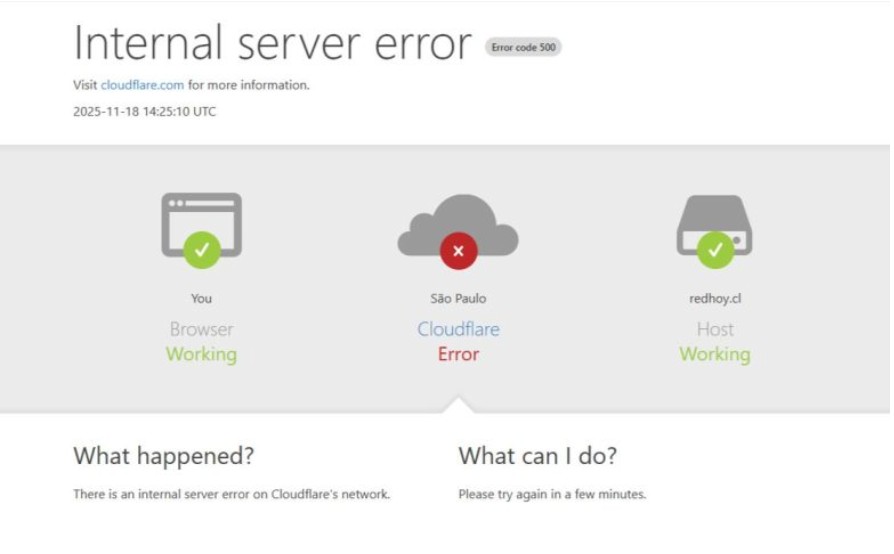
¿Por qué ha caído Cloudflare?
Todo indica que la situación se está estabilizando,pero todavía no hay un diagnóstico público que explique el origen del fallo.
Es de esperar que,como hacen habitualmente,Cloudflare publique un post mortem detallado una vez tengan todas las piezas del rompecabezas.
El primer aviso oficial ha aparecido a las 11:48 UTC,con un mensaje conciso pero lo suficientemente alarmante:Cloudflare había detectado un problema que afectaba a múltiples clientes.
Las pistas eran claras —errores 500 generalizados, el Dashboard inoperativo e incluso la API fallando—,un escenario que solo se ve cuando algo profundo tambalea dentro de su infraestructura.
Apenas un cuarto de hora después,a las 12:03 UTC,la empresa volvía a pronunciarse:continuaban investigando el problema.
Este tipo de actualizaciones,aunque breves,suelen indicar que no se trata de un simple desajuste o una sobrecarga puntual,sino de una incidencia que necesita un despliegue coordinado de ingenieros revisando sistemas,rutas y configuraciones en tiempo real.
A las 12:21 UTC,el tono ha cambiado levemente hacia el optimismo. Cloudflare aseguraba que los servicios comenzaban a recuperarse,pero advertía que los usuarios todavía podrían toparse con tasas de error superiores a las habituales mientras seguían aplicando medidas correctoras. Es una manera sutil de decir:“estamos apagando incendios,pero todavía hay humo”.
Y a las 12:37 UTC,un nuevo comunicado confirmaba que el proceso de investigación continuaba abierto.Todo ello dibuja la típica secuencia de un incidente a gran escala: detección,contención,estabilización progresiva y,finalmente,el largo trabajo de diagnóstico.
Todo indica que la situación se está estabilizando,pero todavía no hay un diagnóstico público que explique el origen del fallo.
Es de esperar que,como hacen habitualmente,Cloudflare publique un post mortem detallado una vez tengan todas las piezas del rompecabezas.
El primer aviso oficial ha aparecido a las 11:48 UTC,con un mensaje conciso pero lo suficientemente alarmante:Cloudflare había detectado un problema que afectaba a múltiples clientes.
Las pistas eran claras —errores 500 generalizados, el Dashboard inoperativo e incluso la API fallando—,un escenario que solo se ve cuando algo profundo tambalea dentro de su infraestructura.
Apenas un cuarto de hora después,a las 12:03 UTC,la empresa volvía a pronunciarse:continuaban investigando el problema.
Este tipo de actualizaciones,aunque breves,suelen indicar que no se trata de un simple desajuste o una sobrecarga puntual,sino de una incidencia que necesita un despliegue coordinado de ingenieros revisando sistemas,rutas y configuraciones en tiempo real.
A las 12:21 UTC,el tono ha cambiado levemente hacia el optimismo. Cloudflare aseguraba que los servicios comenzaban a recuperarse,pero advertía que los usuarios todavía podrían toparse con tasas de error superiores a las habituales mientras seguían aplicando medidas correctoras. Es una manera sutil de decir:“estamos apagando incendios,pero todavía hay humo”.
Y a las 12:37 UTC,un nuevo comunicado confirmaba que el proceso de investigación continuaba abierto.Todo ello dibuja la típica secuencia de un incidente a gran escala: detección,contención,estabilización progresiva y,finalmente,el largo trabajo de diagnóstico.